




This article is maintained by the team at commabot.
Tesseract OCR, an open-source optical character recognition engine, offers a variety of parameters that can be configured to optimize its performance for different text recognition tasks.
In order to better understand the breakdown of the parameters here's a rough architecture of Tesseract:
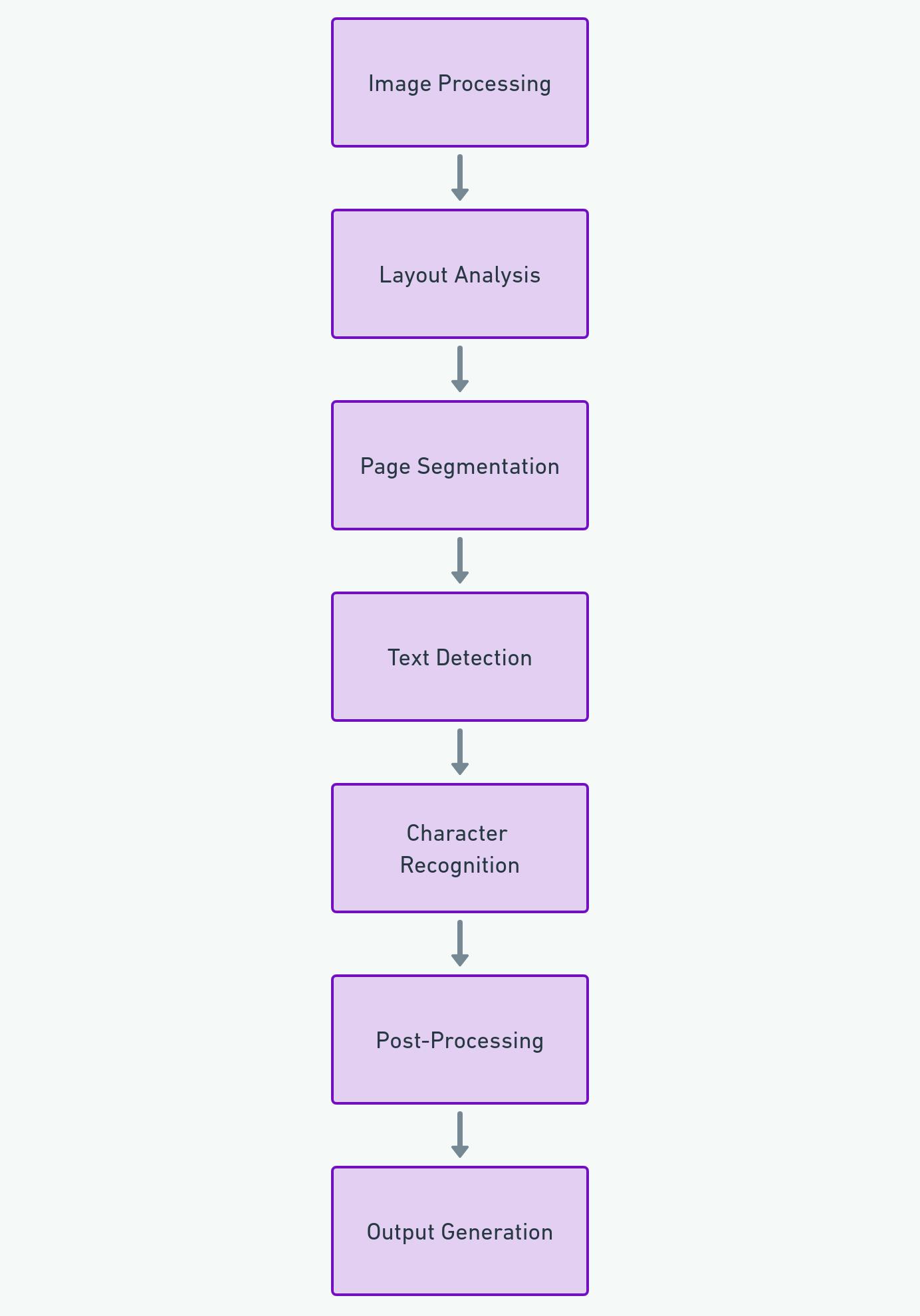
Based on that we can group the parameters into several main categories:
Image Processing Parameters: These parameters are used to preprocess the image before text recognition. This can include binarization, scaling, skew correction, and other image enhancements to improve the accuracy of the OCR process.
Layout Analysis Parameters: These parameters are crucial for determining how the software interprets the physical layout of a page. They guide Tesseract in handling various layout complexities like multiple columns, blocks of text, and the presence of non-textual elements.
Page Segmentation Modes (PSM): These parameters control how Tesseract interprets the structure of the page. They range from considering the entire page as a single block of text to treating it as a single character, word, or line.
Text Detection and Character Recognition Parameters: These parameters specifically affect how Tesseract detects and interprets text in the image. They can be used to tweak the recognition process, such as by specifying language models, dictionary settings, or adjusting heuristic methods for better text recognition.
Dictionary and Language Parameters: These parameters help Tesseract to better understand the context of the text it is scanning, which can greatly improve accuracy, especially for languages with complex grammar or character sets.
Output Formatting: Parameters in this category determine the format of the OCR output. They can control whether Tesseract outputs plain text, hOCR (HTML OCR), TSV (tab-separated values), or other formats. These settings also affect how the text is structured in the output file.
Configuration Files and Customization Parameters: Tesseract allows the use of custom configuration files to set multiple parameters at once. These files can include any of the above parameters and are typically used for specific types of OCR tasks.
Debugging and Logging Parameters: These parameters are useful for debugging and analyzing the OCR process. They can provide detailed logs and outputs that help in understanCharacterding how Tesseract is interpreting and processing the image.
Training and Model Parameters: For advanced users who are training Tesseract with new fonts or languages, there are parameters that control the training process and the creation of new recognition models.
Miscellaneous Parameters: This includes various other parameters that do not fit neatly into the above categories but are useful for specific needs or advanced configurations.
Each of these groups contains numerous individual parameters that can be finely tuned to optimize Tesseract's performance for specific OCR tasks or types of images. The choice of parameters often depends on the nature of the text to be recognized and the quality of the source images.